Payslip & pay stub OCR API
Payslips power mortgage proofs, rental applications, expense audits, and payroll analytics—yet every provider formats them differently. Our document AI reads scanned slips, mobile photos, and digital PDFs so you stop retyping amounts, tax lines, and employer blocks by hand.
Net and gross without spreadsheet drift
Capture base salary, overtime, bonuses, gross totals, and net pay as numbers your systems can sum and reconcile—not fragile copy-paste from PDFs.
Deductions and contributions in one pass
Extract income tax, social security, pension, health insurance, and other withholdings as separate line items when your schema needs them.
Employee and employer identity
Pull employee name, staff or ID number, job title when shown, employer legal name, address, and payroll period dates for KYC-style checks.
Messy scans and multilingual layouts
Handle phone photos, fax-quality scans, and payslips in different languages or statutory formats without maintaining one template per country.
How it works
Get from a raw document to structured JSON in three simple steps.
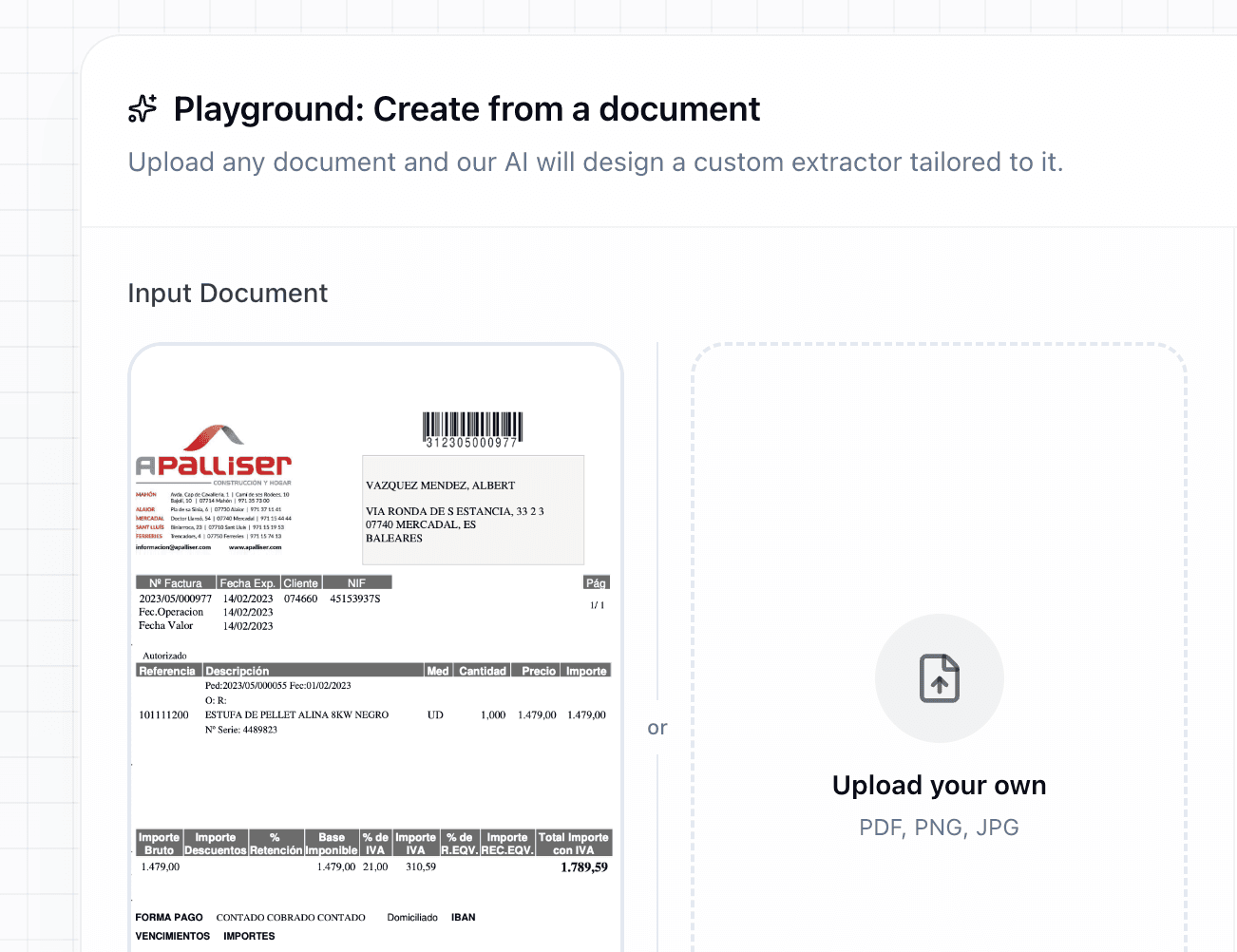
Choose or Upload
Choose OR Upload your own document to generate an schema from it
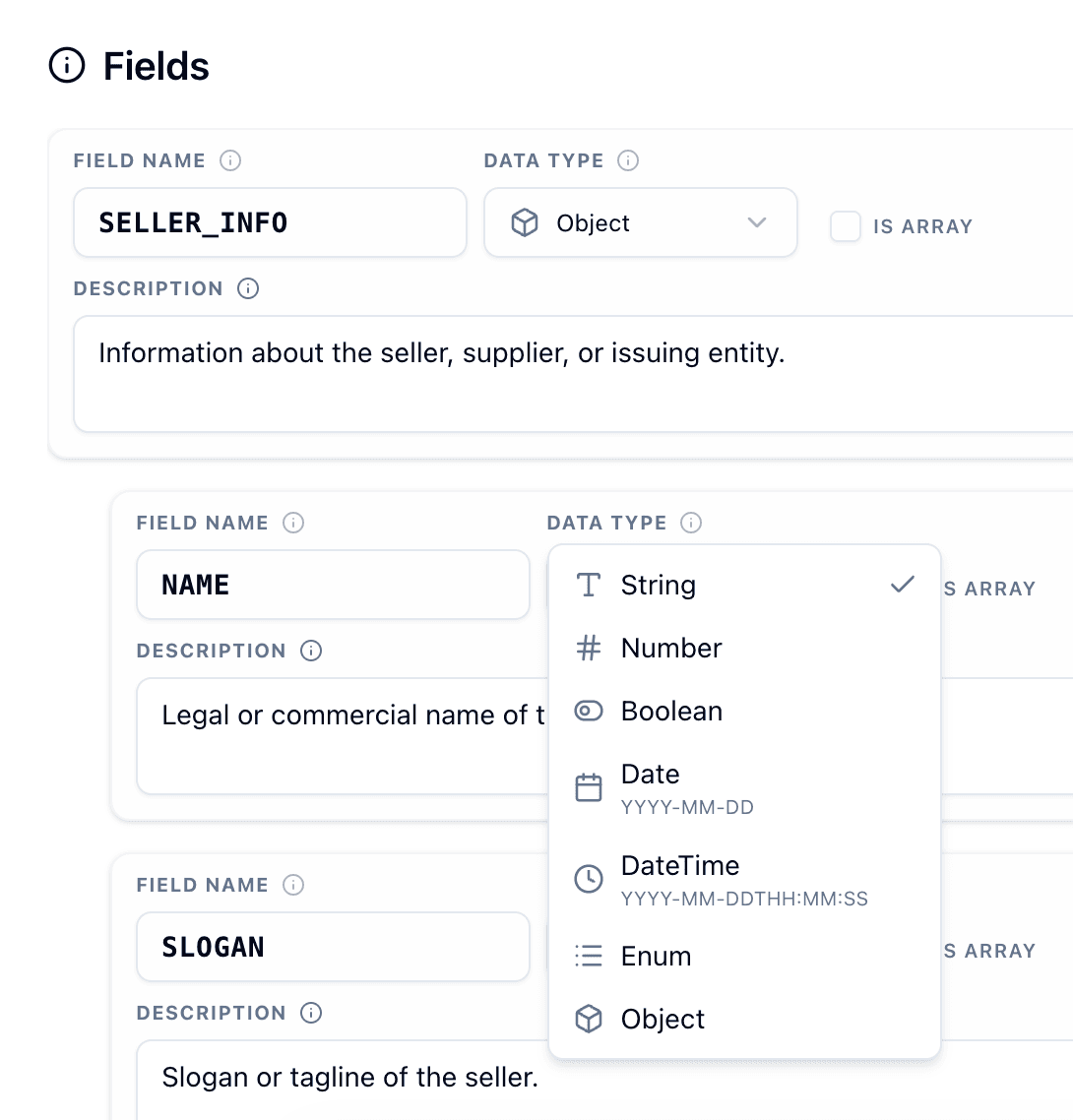
Customize the Schema
curl -X POST "https://api.tiny-idp.com/api/extractors/run/YOUR_EXTRACTOR_ID" \
-H "x-api-key: YOUR_API_KEY" \
-F "files=@/path/to/your/document.jpg"Start Extracting
Try it with a sample payslip or your own document
Upload a payslip or pay stub and see fields extracted automatically. Tune the schema so gross pay, deductions, and employer details map cleanly to your workflows.
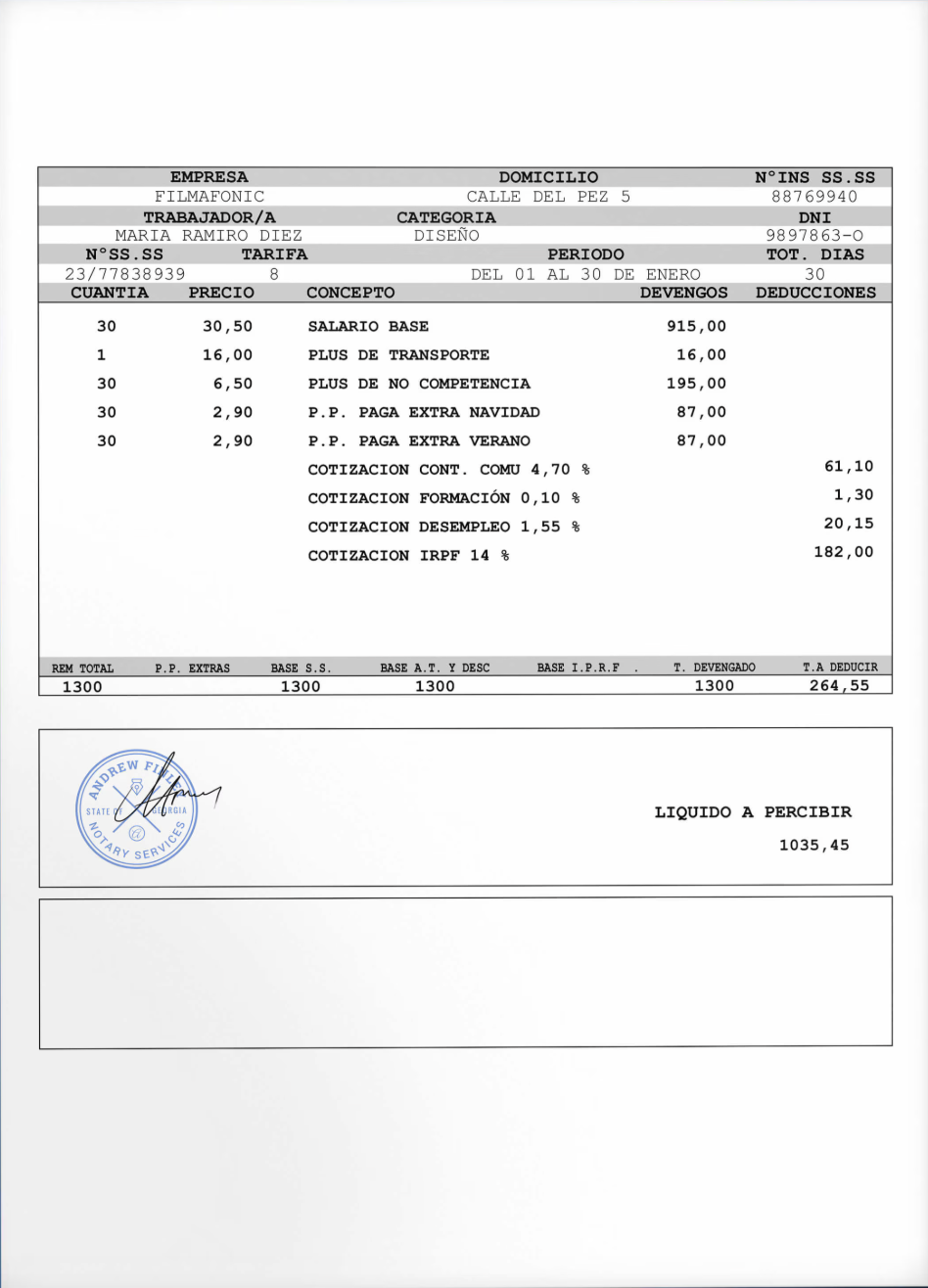
Playground: Create from a document
Upload any document and our AI will design a custom extractor tailored to it.
Input Document
Upload your own
PDF, PNG, JPG
Output & Integration
Ready for production?
Get an API key to start extracting data from your documents in production.
Start from scratch
Know exactly what you need? Define your own JSON schema manually.
Why automate payslip or pay stub documents?
Income proof is everywhere in regulated and high-trust flows: mortgage brokers, landlords, consumer lenders, relocation, and gig or marketplace payouts all ask for recent payslips. Teams still open attachments one by one to copy net pay, employer names, and deduction lines—work that breaks when layouts change or documents arrive as blurry photos.
Automating payslip extraction gives you faster approval cycles, fewer data-entry errors, and consistent fields for risk models and audit trails. It helps banks and neobanks, proptech and HR platforms, and any product that must verify earnings without exposing raw documents to unnecessary manual handling.
Because you control the schema, you can normalize currencies, split composite lines into tax vs. social charges, and extend the model when new statutory blocks appear—without rebuilding brittle regex per country or per payroll provider.
90% Faster
Reduce processing time from minutes to seconds.
Higher Accuracy
Eliminate manual entry errors and typos.
What fields can be extracted from a payslip or pay stub?
You can extract employee identifiers—full name, employee or payroll number, department or job title when printed—and employer details: legal name, address, tax or company registration references where shown. For the pay period you can capture period start and end dates, pay date, and payment frequency. Financial lines typically include gross pay, itemized earnings (base, overtime, commissions, bonuses), itemized deductions (income tax, national insurance or social security, pension, health or other benefits), employer contributions if listed, year-to-date aggregates when present, and net pay. With a custom schema you can map local labels to your canonical fields, enforce rounding rules, and flag missing proofs of income automatically.
Commonly extracted fields include:
Simple, Transparent Pricing
No hidden fees. No monthly minimums. Pay only for what you extract.
Usage-Based
Simple pay-as-you-go pricing. No monthly commitment.
- Unlimited extractors
- Pre-built & custom extractors
- OCR and AI technology
- GDPR compliant
- EU-hosted infrastructure
- Standard support
Enterprise
Tailored pricing for high-volume scenarios. Get SLA guarantees, on-premise deployment, and dedicated support — reach out and we'll put together a plan that fits your scale.
- Custom pricing models
- SLA guarantees
- On-premise deployment options
- Custom integration support
- 24/7 dedicated support
- Priority feature requests
All prices exclude VAT. Volume discounts apply automatically.
Enterprise-grade Compliance & Security
We take data privacy seriously. Tiny IDP is built from the ground up to meet the strictest European data protection standards.
Zero Data Retention
We don't store your documents, images, or predictions. Data is processed in-memory and immediately discarded.
GDPR Compliant
Full compliance with European data protection regulations (GDPR) for your peace of mind.
EU-Based Infrastructure
All data is processed and hosted exclusively in secure European data centers.
Do you need a custom OCR?
We support custom extractors! Define your own fields, rules, and logic to extract data from any type of document.